To Be Greedy, or Not to Be - That Is the Question for Population Based Training Variants [TMLR]
TL;DR Bayesian PBTs optimize the greedy objective more effectively than non-Bayesian PBTs, this can be good or bad (depends on the task & hyperparams) | Paper | Code
Population Based Training (PBT) optimizes a hyperparameter schedule by evolving a population of solutions (weights + hyperparams). It is general, parallel, and scalable. It has been extended to leverage Bayesian Optimization (PB2, PB2-Mix, BG-PBT) or be less greedy (FIRE-PBT)
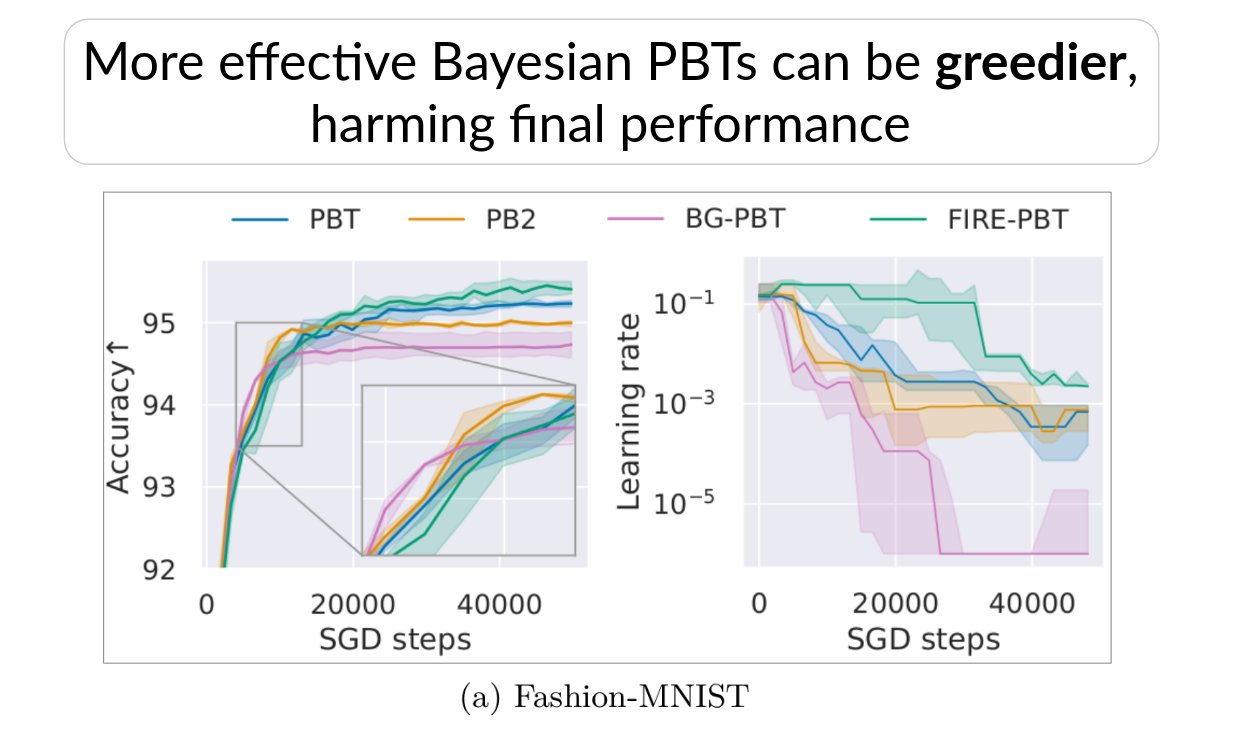
We find that from the theoretical perspective, Bayesian PBTs are guaranteed to asymptotically approach the returns of the greedy schedule (rather than the optimal one, as claimed in prior work).
Mechanistically, the number of hyperparameter update steps can influence the greediness, and the absolute & relative performance of PBT variants (despite constant total compute). The trends are clear for image classification where only the learning rate is optimized…
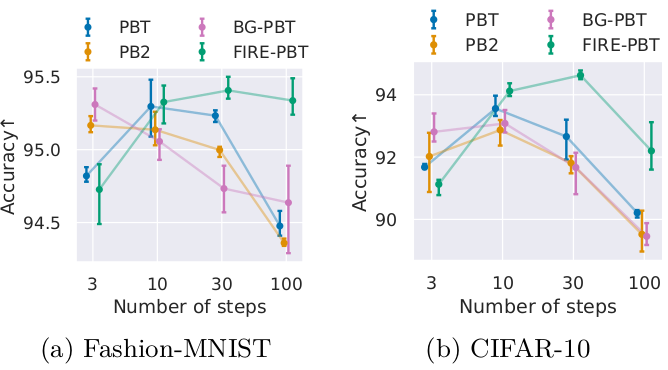
… but not so clear for reinforcement learning (or image classification with larger search spaces)
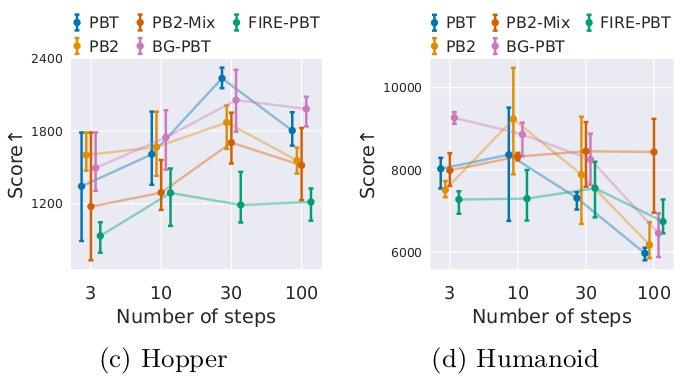
Our impartial evaluation showed that no PBT variant is substantially better than others across tasks and settings (note that one limitation of our work is not fully exploring all hyperparameters of PBT variants)
![]()
Check out the paper for details!
We also release our code containing task-agnostic implementations of five PBT variants, hopefully making future research and comparison of PBT variants easier!
P.S. Thank you to my supervisors and coauthors, Tanja Alderliesten and Peter Bosman.